Réflexion en cours sur la façon d’articuler une bibliothèque numérique (ici, là). Tentative de trouver une nouvelle façon de référencer les documents, d’éviter les protocoles extérieurs (DOI), de ne pas se perdre dans la multiplicité des formats (papier/ISBN, numérique/epub-html-xml-pdf-doc-pff!).
N’ai pas trouvé de réponse. (Pas encore ?)
Quelques explications supplémentaires. Mon intérêt pour Zotero est fragilisé par la difficulté de renseigner tous les champs, par son (actuel) confinement à Firefox, par une interface qui me semble toujours trop directement héritée des Endnote de ce monde (quelle horreur). Mon problème : comment gérer à la fois des pdf d’articles, des epubs d’œuvres, des scans maison d’articles et de chapitres de collectifs, des pdf d’entrées de blog, des documents transmis par des collègues, le tout sur plusieurs plateformes (tablettes, portables, nuages) ? Quel mode de référencement permettrait de ne pas alourdir la gestion (pas question de tout coter à la Dewey !) tout en tenant compte des nouveaux modes de lecture, des éparpillements sur plusieurs appareils ?
Cette problématique m’a conduit à tenter de sérier les paramètres de référencement en contexte numérique. Point de départ (point de référence) : le fichier informatique. Comment le référence-t-on, de la façon la plus simple ? On donne son titre de fichier, son type (pdf, doc, epub, odt, xls…) et son emplacement (où se trouve-t-il, sur quel volume, à quelle hiérarchie ?). Ainsi référencé, le fichier peut être parfaitement désigné dans le monde informatique : pas d’erreur entre deux entités portant le même nom mais pas la même extension (.doc vs .pdf, fichier simple vs dossier, etc.) ; identité basée sur le titre ; possibilité de confusion limitée à l’emplacement où il se trouve (le path indiquant clairement une autre variable d’identité : dans le dossier X, dans le sous-dossier Y). Petite synthèse partielle :

Cette préoccupation de localisation et d’identité est toutefois propre à une logique informatique. Si l’on tente de restreindre plus spécifiquement à un document numérique, perçu comme modalité de transmission d’un contenu, peut-on en arriver à une lecture différente de ces paramètres ? Inspiration, pour ce déplacement, de l’article d’Hubert Guillaud sur « L’industrialisation numérique », mais en particulier le commentaire de Karl Dubost qu’Hubert reprend dans son article :
Le format est un conteneur du texte. La capacité à modifier ces documents, à l’interactivité, etc. ne dépend pas du conteneur, mais du moteur de rendu (navigateur, logiciel client, etc.) Que le texte soit en XML, en html, en DB, en texte seul, importe peu.
Le fichier n’est pas intéressant en lui-même ; l’intérêt est porté sur l’expérience du fichier. De la sorte, pour l’utilisateur lambda, le référencement est possible par ce qu’il perçoit. Non pas un titre de fichier mais un titre affiché. Non pas un type de fichier (qui est donc un « conteneur ») mais le cadre dans lequel le document est intégré / objet d’un processus d’affichage (le « moteur de rendu »). L’emplacement exact du fichier importe peu, c’est la logique développée par toutes les applications de bibliothèque qui a préséance (sur OS X, pour ne prendre que cet exemple : on se moque où sont rangées nos photos classées dans iPhoto, on perd de vue où sont stockées les pièces musicales gérées par iTunes). Ce qui prend de l’importance, me semble-t-il, c’est la temporalité de l’expérience : ce cadre de lecture associé à un moment donné. Sans trop savoir comment l’app Kindle gère les lectures des œuvres qu’elle supporte, on peut prétendre que c’est la combinaison d’un paramètre spatial interne (à quelle page) et d’un paramètre temporel (à quel moment), pour synchroniser les lectures et s’assurer que le lecteur retrouve l’espace-temps de sa dernière lecture.
Depuis l’expérience de lecture du document numérique, les paramètres déterminants semblent bien différents des logiques hiérarchiques et binaires du filesystem-type en informatique.

Il n’en reste pas moins qu’aux yeux de tout un chacun (je peux servir d’échantillon) il y a une distance entre ce qui est affiché (donc tous les artifices de l’affichage : mise en page, typo, graphisme, fonctions annexes) et le contenu pour ce qu’il est, le texte lui-même. En ce sens, il existerait une troisième incarnation possible, plus minimale que le document numérique et le fichier informatique. Y a-t-il possibilité de s’y référer également ? L’identité reposerait ainsi sur le titre du texte, tel qu’il figure dans le texte même. Le type renverrait à la syntaxe du texte : à la fois la syntaxe déterminée par un code linguistique et la mise en ordre du texte (disposition recueillistique, assemblage des chapitres ou des fragments) ; à la fois la nature de cette organisation et sa qualité (style, richesse, réussite). Le référencement hiérarchique ou temporel, dans cette troisième incarnation, ne peut être autre que le code lui-même, l’écriture du texte : lorsqu’on se reporte au texte lui-même et que son encodage importe peu, c’est la lettre qui nous importe — d’où ces requêtes pour une séquence exacte de lettres et de mots, inscrites entre guillemets dans notre moteur de recherche favori. L’identité du texte réside dans cette combinaison unique de caractères, de ponctuation et d’espaces, comme Borges l’avait bien pressenti dans sa « Bibliothèque de Babel ».

Ainsi placées, ces incarnations se démarquent par leur relation plus ou moins étroite avec le support, avec le code, avec l’interface. Le fichier informatique semble se cantonner à la stabilité d’une relation contenu-contenant : on pourrait décrire celle-ci comme une incarnation donnée. Par opposition, le document numérique serait toujours inscrit dans une expérience, d’où cette temporalité et la possibilité de couches de sens superposées mais singulières (les annotations, principalement) ; la relation serait celle d’une occurrence. En revanche, revenir à la lettre du texte, c’est révéler sa nature d’artefact (une relation immanente ?), où la dimension construite, produite du texte se donne comme principale caractéristique (comme dénominateur commun en regard d’autres textes).

Les fondamentalistes informatiques diront que le filesystem a toujours préséance (même s’il est dissimulé) ; les littéraires diront que le texte importe plus que ses incarnations ; les fervents de culture numérique prôneront une mise en valeur de l’expérience numérique. Positions irréconciliables ? Sûrement pas, parce qu’elles parlent des facettes d’une expérience complexe et en décrivent les visages multiples mais complémentaires.
Reste à imaginer comment construire sa bibliothèque — en restreignant à un mode d’incarnation ? en documentant les trois visages à la fois ? Les usages varient sûrement d’une discipline à l’autre, d’un usage à l’autre… Mais les trois modes d’accès doivent pouvoir cohabiter.

 L’ambition d’étudier la culture numérique est à la fois démesurée et nécessaire. Tentaculaire, la culture numérique vient rejoindre des dimensions multiples des pratiques artistiques et culturelles d’aujourd’hui, qu’elles soient totalement ancrées dans le champ numérique ou seulement en marge.
L’ambition d’étudier la culture numérique est à la fois démesurée et nécessaire. Tentaculaire, la culture numérique vient rejoindre des dimensions multiples des pratiques artistiques et culturelles d’aujourd’hui, qu’elles soient totalement ancrées dans le champ numérique ou seulement en marge.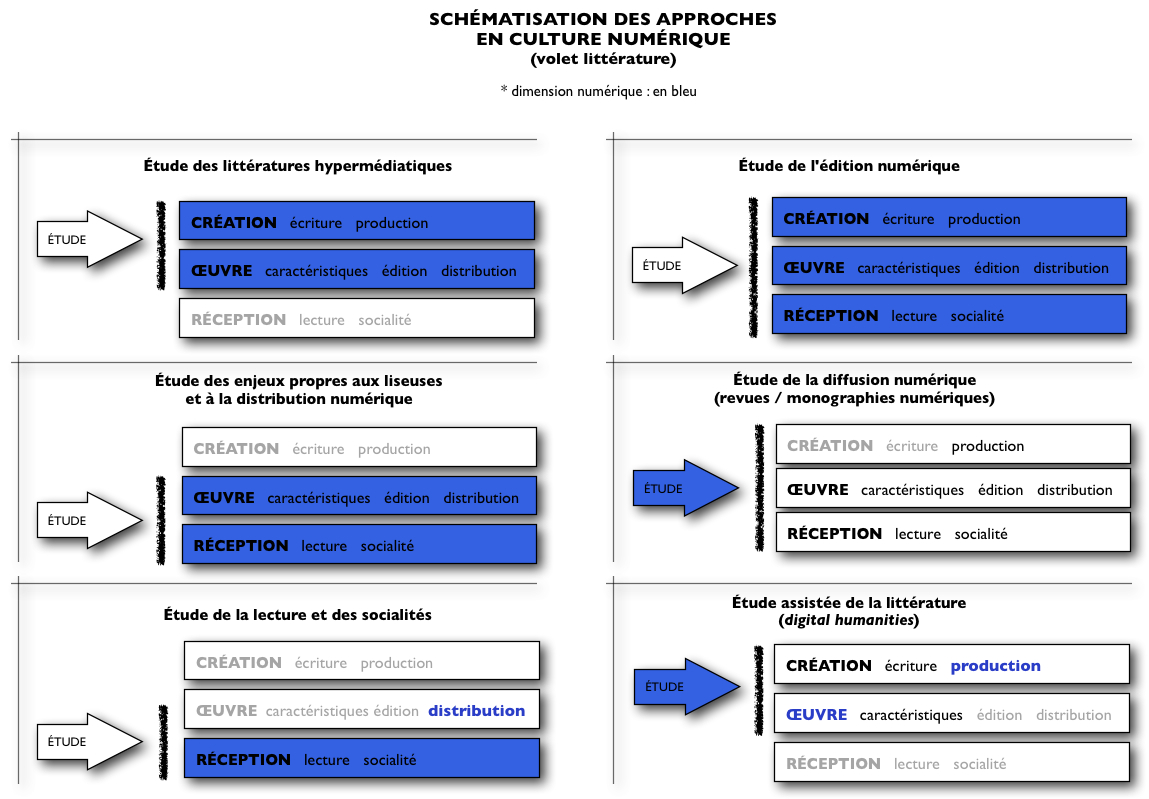
 « À travers la porte vitrée de la salle d’attente… »
« À travers la porte vitrée de la salle d’attente… »